| Informática Instrumental Material de Referência |
| Introdução a Bancos de Dados |
| Introdução |
Considere o caso que era comum há alguns anos atrás: uma empresa mantém informações sobre todos os seus funcionários e produtos em arquivos. Essas informações são manipuladas por programas independentes, ou seja, existe um programa para consultar dados dos funcionários, outro para catalogar dados dos novos produtos, etc. Esses programas foram construídos para atender as necessidades específicas da empresa numa certa época. À medida em que novas necessidades aparecem, novos programas independentes são criados. Esse sistema de processamento de dados possui diversos problemas:
-
como os programas e arquivos são criados por programadores diferentes, a mesma informação pode estar duplicada em vários lugares, o que pode gerar inconsistência dos dados. Por exemplo, o telefone de um empregado pode ser um para um sistema e outro diferente para um outro sistema. Os dados são inconsistentes porque as várias cópias dos mesmos não são iguais.
-
este ambiente não permite consulta aos dados de forma eficiente. Se é necessário saber quantos funcionários recebem salários maiores que um determinado valor e esta funcionalidade não está implementada, seria necessário implementá-la através de mais um programa específico ou obter manualmente a informação.
-
uma vez que os dados estão espalhados em vários arquivos e estes podem estar em diferentes formatos, é difícil escrever novos programas para consulta conveniente destes dados.
-
além destes problemas pode-se destacar a dificuldade de se trabalhar com múltiplos usuários utilizando arquivos ao mesmo tempo e ainda os problemas de segurança decorrentes.
Estas dificuldades levaram ao desenvolvimento dos sistemas gerenciadores de bancos de dados.
Um sistema de gerenciamento de bancos de dados (SGBD) consiste numa coleção única de dados inter-relacionados e um conjunto de programas para acessar esses dados. A coleção de dados é comumente chamada de banco de dados. O principal objetivo de um SGBD é proporcionar um ambiente conveniente para retirar, acessar e armazenar informação no banco de dados.
Sistemas de banco de dados são concebidos para gerenciar grandes quantidades de informação. O gerenciamento dos dados envolve tanto a definição de estruturas para armazenamento da informação como a provisão de mecanismos para manipulá-la. O SGBD deve proporcionar a segurança das informações armazenadas no banco de dados, mesmo em caso de parada no sistema ou de tentativas de acessos desautorizados.
| Idéias Básicas |
O mundo está cheio de coisas. Nós abstraímos coisas semelhantes e chamamos estas abstrações de objetos. Quando formulamos estas abstrações, sobre essas coisas, por limitação própria, somos levados a desconsiderar vários detalhes sobre os mesmos. Os detalhes que somos capazes de perceber são agrupados de acordo com conceitos e julgamentos sobre o que achamos ser semelhante. O nosso conceito do que constitui os critérios apropriados para determinar a semelhança depende dos objetivos que temos. Por exemplo, uma pessoa pode ser entendida como um empregado de uma empresa, uma paciente de um hospital, um criminoso em uma delegacia, etc...
Assim, podemos dizer então que um objeto é uma abstração de um conjunto de coisas do mundo real, de forma que:
-
todas as coisas do mundo real do conjunto, chamadas instâncias, tenham as mesmas características.
-
todas as instâncias estejam sujeitas às mesmas normas.
Por exemplo, vamos pensar no objeto Livro. Temos que pensar em como caracterizar um livro. Podemos dizer que um livro possui um título, um autor e uma editora. A partir de então, classificamos os livros de acordo com estes atributos. Todos os livros possuem essas mesmas características.
| Título | Autor | Editora |
| O Alquimista | Paulo Coelho | Rocco |
| Presença de Anita | Mário Donato | Objetiva |
| Antes do baile verde | Lígia Fagundes Telles | Rocco |
Quando dizemos que os objetos seguem às mesmas normas, queremos definir operações simples, por exemplo, consultas, sobre os dados. Neste caso, poderíamos saber quais os nomes dos livros da editora "Rocco" ou quantos livros o autor "Paulo Coelho" publicou.
| Identificando objetos |
A identificação dos objetos é uma tarefa bastante fácil. Devemos começar perguntando "Quais são as coisas que compõem este problema?". A maioria das coisas pode ser classificada como um coisa tangível, um incidente ou uma especificação. As coisas tangíveis são os objetos mais fáceis de ser achados. Podemos citar como exemplos um automóvel, um livro, um computador entre outros. Os incidentes são usados para representar uma ocorrência ou um evento - algo que acontece em um determinado período. Por exemplo, uma compra, venda ou aluguel. As especificações surgem mais freqüentemente em aplicações relacionadas à peças, estoque ou fabricação, como por exemplo, especificações de aparelhos elétricos ou de peças mecânicas.
| Atributos |
Um atributo é a abstração de uma única característica possuída pelas entidades que foram classificadas como um objeto, ou seja, uma característica comum a todas essas entidades.
Se os carros podem ser verdes, azuis ou brancos, eles têm uma propriedade em comum, no caso, a cor. Dizemos então que a cor pode ser um atributo do objeto carro. Dependendo do problema, poderíamos definir outros atributos para o objeto carro, tais como peso, número da placa, fabricante, etc...
O ideal é obter um conjunto de atributos que sejam:
-
completos - abrangem todas as informações pertinentes ao objeto que está sendo definido.
-
fatorados - cada atributo capta um aspecto separado da abstração do objeto.
-
independentes - os atributos assumem seus valores independentes um do outro.
Os atributos podem ser identificados de duas formas. Você pode se perguntar que características possuem as instâncias do mundo real que foram abstraídas para se tornar objetos? Você também pode se perguntar que informação precisaria conhecer sobre uma entidade do mundo real para dizer que é uma instância deste objeto?
Os atributos que você identificar podem ser classificados em três categorias, dependendo da espécie de informação captada por cada um deles:
-
descritivos: refletem características intrínsecas ao objeto.
-
nominativos: nomes ou rótulos que identificam o objeto.
-
referenciais: fatos que ligam uma instância de um objeto a uma instância de outro objeto.
Vejamos a definição do objeto Empregado mostrado abaixo:

Um objeto do tipo Empregado possui como atributos um código, salário, endereço, o nome do departamento no qual trabalha e seu nome.
Como podemos classificar cada atributo desta entidade?
Sabemos que os atributos descritivos se referem a características intrínsecas a cada objeto. São atributos descritivos do Empregado, o salário e o endereço. Os atributos nominativos fornecem fatos relativos aos nomes e rótulos de um objeto. Podemos observar que podemos mudar os nomes ou rótulos de cada objeto sem mudar nada mais, ou seja, podemos dar um novo código ao empregado que ele continuará sendo o mesmo. São atributos nominativos do Empregado, seu nome e código. Os atributos referenciais captam os fatos que ligam uma instância de um objeto a uma instância de um outro objeto. Neste caso, o nome do departamento no qual o empregado trabalha o liga a uma instância de uma entidade Departamento.
| Identificadores |
Um conjunto de um ou mais atributos que unicamente distingue cada instância de um objeto é chamado identificador para aquele objeto. Um identificador pode ser chamado de chave. No exemplo que demos anteriormente, o nome do empregado não pode ser considerado identificador (chave) do objeto Empregado pois pode haver mais de uma instância com o mesmo nome. Pode haver dois empregados com o nome João da Silva. O código do empregado pode ser considerado chave do objeto, pois não existem dois empregados com o mesmo código. Pode haver um empregado chamado João da Silva com o código 123 e outro empregado também chamado João da Silva, porém com código 345.
| Relacionamentos |
Durante a construção de um modelo de informação, estamos interessados em identificar as associações entre as coisas do mundo real e em refletir essas associações em nosso modelo como relacionamentos precisamente determinados.
Por exemplo, suponha que em determinado contexto podem ser identificados dois objetos: um computador e um processador. Podemos dizer que esses dois objetos estão relacionados, pois um computador possui um ou mais processadores e um processador é parte de um computador.
Um relacionamento é uma abstração de um conjunto de associações que existe entre espécies diferentes de coisas do mundo real.
Os relacionamentos que envolvem somente dois tipos de objetos podem ser classificados em três formas, dependendo do número de instâncias de cada objeto que participam de cada relacionamento.
Os relacionamentos podem ser:
-
um para um: um departamento possui um diretor
-
um para muitos: um departamento possui muitos empregados
-
muitos para muitos: autores escrevem livros
Essa multiplicidade de cada relacionamento é também chamada de cardinalidade.
Na próxima seção, descreveremos o modelo entidade-relacionamento, muito usado para modelar sistemas de bancos de dados.
| Modelando um problema usando o modelo Entidade - Relacionamento |
Suponha que você seja dono de uma locadora de vídeos. Você deseja armazenar dados de estoque e empréstimos dos seus filmes.
Inicialmente, você deve pensar quais coisas do mundo real fazem parte do universo de sua locadora de vídeos. O primeiro objeto que você pensa é a fita. No modelo entidade-relacionamento, os objetos são chamados de entidade. Portanto, podemos dizer que a Fita é uma entidade do seu modelo. Em seguida, você deve pensar em como caracterizar uma fita. Você pode chegar a conclusão de que cada fita possui:
-
um nome
-
uma duração
-
um diretor
-
um preço de compra
Esses são os atributos da entidade Fita. Você poderia ter pensado em outros ou em mais atributos, mas por enquanto, manteremos somente esses atributos para a entidade Fita.
Nosso primeiro passo será construir um diagrama entidade - relacionamento que modele o banco de dados. O item básico que o modelo entidade-relacionamento representa é uma entidade, que é algo do mundo real com uma existência independente (objeto). Uma entidade pode ser um objeto com uma existência física - uma pessoa particular, um carro, uma casa ou um empregado - ou pode ser um objeto com uma existência conceitual - uma empresa, um emprego ou um curso universitário. Cada entidade possui atributos - as propriedades particulares que a descrevem.
Para construir um diagrama entidade - relacionamento, devemos definir quais entidades participarão deste diagrama, seus atributos e relacionamentos.

Esta é a definição da entidade Fita e seus atributos. Poderíamos criar várias instâncias da entidade Fita como mostrado abaixo:
| NomeFita | Duração | Diretor | Preço |
| Hannibal | 131 | Ridley Scott | 24,90 |
| Falcão Negro a Solta | 144 | Ridley Scott | 20,90 |
| Gladiador | 155 | Ridley Scott | 23,90 |
| Blade Runner | 122 | Ridley Scott | 16,90 |
Como você pode notar, pode haver uma repetição desses atributos, ou seja, pode haver diversos filmes que possuem o mesmo diretor. Assim, podemos concluir que eles deverão fazer parte de uma entidade separada. Se criarmos uma entidade separada Diretor, teremos então o diagrama mostrado abaixo:
Uma entidade normalmente possui um atributo cujos valores
são distintos, isto é,
No nosso exemplo, como nenhum dos atributos definidos é adequado para ser usado como chave das entidades, criaremos para cada uma delas, um atributo "código", que será único para cada uma delas.

Um relacionamento é uma associação entre várias entidades. Devemos agora relacionar as entidades. Como cada fita possui um único diretor, devemos criar um atributo "CódigoDiretor" na entidade Fita para se relacionar com o atributo de mesmo nome na entidade Diretor.

Todo relacionamento possui uma cardinalidade. No exemplo acima, o filme da fita é dirigido por apenas um diretor (1-1) e um diretor pode dirigir de zero a muitos filmes (0-N), ou seja, todo filme é dirigido por um diretor e este é único, já um diretor pode dirigir N filmes (inclusive nenhum). Podemos dizer então que a cardinalidade deste relacionamento é "zero para n". (Pode haver um diretor que não dirigiu nenhum filme).
O modelo entidade-relacionamento é uma forma de se representar os bancos de dados. Na seção seguinte, descreveremos uma outra forma de como implementar um banco de dados, utilizando um sistema de gerência de banco de dados relacional (o tipo de banco de dados atualmente mais comum).
Podemos ter um diagrama de entidade de dados que não leve em consideração o sistema de banco de dados que será utilizado (chamado modelo conceitual) como é o caso dos modelos apresentados até então.
| Modelo Relacional |
Podemos ter modelos que se aplicam somente a um certo tipo de sistema de gerência de bancos de dados, como os relacionais. O modelo relacional representa o banco de dados como um conjunto de tabelas que podem se relacionar. Cada tabela é composta por um conjunto de valores divididos pelos seus diversos campos. Abaixo, por exemplo, temos a representação da tabela Fita no sistema de bancos de dados Access.
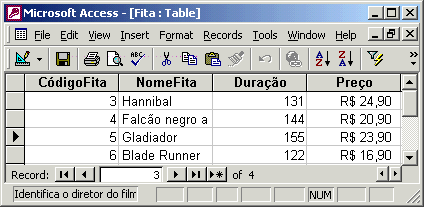
Uma vez feito o modelo do banco de dados através de um diagrama de entidade - relacionamento, a passagem para o modelo relacional é praticamente direta.
Assim, cada entidade criada no modelo entidade-relacionamento será considerada uma tabela no Access.
As colunas de uma tabela no modelo relacional (campos) correspondem aos atributos do modelo entidade-relacionamento. Quando definimos uma tabela, definimos o nome de cada campo, seu tipo e podemos dar uma descrição para este campo.
Abaixo, temos em detalhes informações sobre o campo "NomeFita". Este campo é do tipo Texto.
Na parte debaixo da tela, temos as propriedades de cada campo. Podemos destacar algumas:
Tamanho do campo: usado para definir o tamanho do campo. Por exemplo, o campo "NomeFita" da tabela "Fita" possui tamanho 100, ou seja, podem ser inseridos nesta tabela nomes de fitas de até 100 caracteres.
Valor padrão: valor usado para iniciar o campo. Por exemplo, o campo "NomeFita" não possui valor padrão.
Requerido: indica se é obrigatório definir um valor para o campo ou se o valor do campo pode ser deixado em branco. É obrigatório sempre definir um valor para o campo "NomeFita".
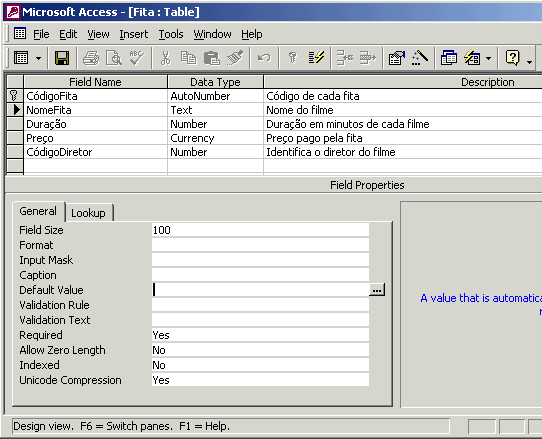
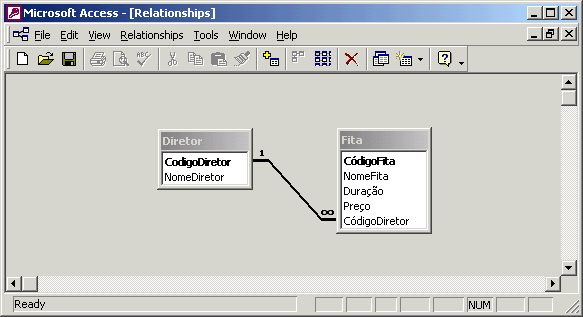
Durante a criação de cada tabela no modelo relacional, devemos também definir qual atributo será a chave da tabela. Neste exemplo, o atributo "CódigoFita" é considerado a chave da tabela Fita (o atributo chave é marcado com o símbolo de uma chave à esquerda do nome). Devemos criar também os atributos que serão usados no relacionamento com outras tabelas. Por exemplo, o relacionamento entre as tabelas Diretor e Fita possui cardinalidade 1..N. Sempre que você se deparar com um relacionamento deste tipo, você deve inserir na tabela que está do lado "N" do relacionamento, um atributo que se relacione com a chave primária da outra tabela. Neste caso, foi inserido na tabela Fita o atributo "CódigoDiretor", para se relacionar com a chave primária "CódigoDiretor" da tabela Diretor.
No Access, após a criação de tabelas, chaves e relacionamentos, é mostrado o seguinte modelo:
| O que é possível fazer com o Microsoft Access |
O Microsoft Access, como qualquer outro sistema gerenciador de bancos de dados, provê uma série de facilidades que tornam o tratamento das informações contidas nos bancos de dados muito mais fácil. O Microsoft Access trabalha com os recursos: consultas, relatórios e formulários.
Vamos supor que a tabela Fita deste banco de dados possua estes dados, onde CódigoDiretor igual a 1 refere-se ao diretor Ridley Scott.
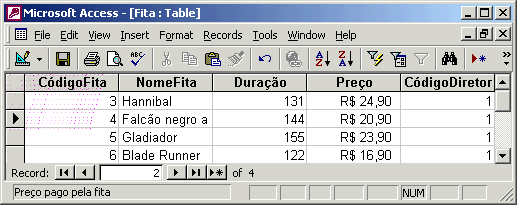
Poderíamos fazer diversas consultas aos dados deste banco, como por exemplo, poderíamos querer saber os dados dos filmes cuja duração seja menor que 135 minutos ou cujo preço seja maior que 21,00 reais. Essas consultas podem ser visualizadas abaixo:
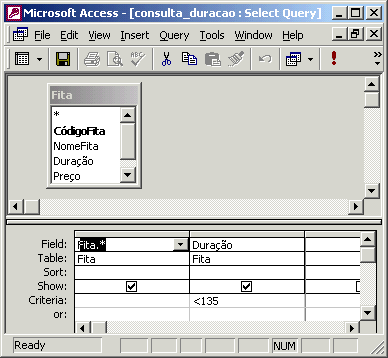

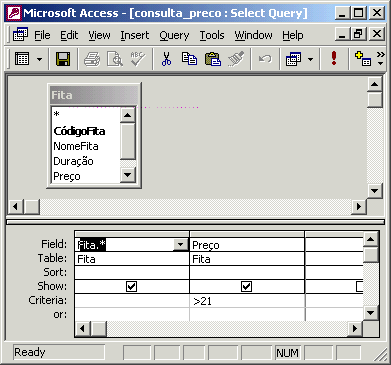

As consultas podem ser visualizadas na própria tela do computador, porém, há uma forma muito melhor de se visualizá-las: através de relatórios. Os relatórios normalmente trazem os dados que satisfazem a um certo critério de uma consulta. Por exemplo, poderíamos querer imprimir um relatório com todos os filmes da locadora que custaram mais que 21 reais como mostramos abaixo.

Além de relatórios, você pode construir também formulários. Formulários são muito usados para entrada de dados em seu banco de dados. Eles possuem uma interface que permite que o usuário de um sistema que utiliza o banco de dados entre dados de forma fácil e simples. Abaixo, mostramos um formulário que contém os filmes dirigidos por Ridley Scott.
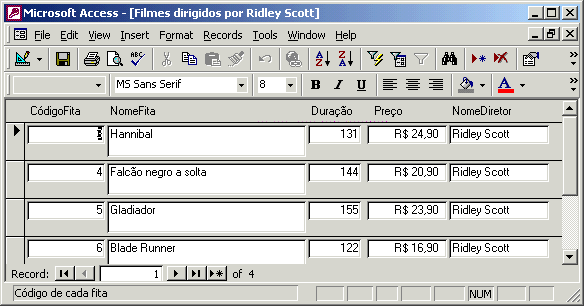
| Normalização |
Podemos definir normalização como o processo formal passo a passo que examina os atributos de uma tabela, com o objetivo de evitar anomalias observadas na inclusão, exclusão e alteração de dados. Este processo tem como objetivos:
-
minimização de redundâncias e inconsistências.
-
facilidade de manipulações do banco de dados.
-
facilidade de manutenção do sistema de informações.
Para evitar esses problemas, o projeto de um banco de dados deve passar pela fase de normalização. Podemos definir a normalização como o processo de transformação das relações (tabelas e relacionamentos) em novas relações pela aplicação de quebra de tabelas.
Este processo tem como conseqüências:
-
problemas de anomalias e inconsistências diminuem
-
relações se tornam simplificadas e regulares
-
aumento de integridade dos dados
É importante ressaltar que se o processo de normalização for feito corretamente, ao fazer uma nova aplicação não é necessário refazer o banco de dados.
O processo de normalização consiste de três fases que detalharemos agora.
| Primeira Forma Normal |
A primeira forma normal (1a FN) diz que todos os atributos admitem apenas valores atômicos, ou seja, os valores devem ser simples, não repetidos.
Considere o exemplo abaixo:
Devemos armazenar em uma tabela as quantidades de três produtos diferentes de alguns fornecedores diferentes. Poderíamos ter a estrutura mostrada abaixo:
| Código_Fornecedor* | Produto1 | Quantidade1 | Produto2 | Quantidade2 | Produto3 | Quantidade3 |
| F1 | P1 | 200 | P2 | 300 | ||
| F2 | P3 | 100 | ||||
| F3 | P1 | 200 | P3 | 400 | P5 | 400 |
Como podemos ver, existem valores repetidos desta forma. Quanto maior fosse o número de produtos diferentes, mais colunas esta tabela deveria ter. Esta tabela não se encontra na Primeira Forma Normal, pois apresenta atributos não atômicos. Para ser colocada de forma a obedecer a Primeira Forma Normal, ela deve ser reestrutura da seguinte forma:
| Código_Fornecedor | Código_Produto | Quantidade |
| F1 | P1 | 200 |
| F1 | P2 | 300 |
| F2 | P3 | 100 |
| F3 | P1 | 200 |
| F3 | P3 | 400 |
| F3 | P5 | 400 |
Podemos definir o seguinte procedimento para verificar se uma tabela obedece à primeira forma normal.
Procedimento (Primeira Forma Normal)
-
Identificar a chave primária da tabela.
-
Identificar o grupo repetitivo e removê-lo da tabela.
-
Criar uma nova tabela com a chave primária da tabela anterior e a do grupo repetitivo.
| Segunda Forma Normal |
Em primeiro lugar, para que a segunda forma normal seja obedecida, a primeira forma normal deve ser satisfeita também. A segunda forma normal (2a FN) diz que cada atributo não chave deve ser dependente de toda a chave primária, ou seja, não podem existir atributos que não dependam da chave ou dependam apenas de parte da chave primária. Vejamos o exemplo abaixo:
Continuando o exemplo citado anteriormente, queremos agora cadastrar a cidade onde estão localizados os fornecedores. A tabela passaria então a ter a seguinte estrutura:
| Código_Fornecedor | Código_Produto | Quantidade | Cidade |
A chave desta tabela é formada pelos campos "Código_Fornecedor" e "Código_Produto". O atributo "Cidade" (onde se localiza o fornecedor) não depende totalmente da chave primária, depende somente do atributo "Código_Fornecedor", que é apenas parte da chave. Assim, a tabela mostrada desta forma, não obedece a Segunda Forma Normal. Para que isto aconteça, devemos criar duas tabelas:
| Código_Fornecedor | Código_Produto | Quantidade |
| Código_Fornecedor | Cidade |
Podemos definir o seguinte procedimento para verificar se uma tabela obedece à segunda forma normal.
Procedimento (Segunda Forma Normal)
-
Identificar os atributos que não são funcionalmente dependentes de toda a chave primária.
-
Remover da tabela todos esses atributos identificados e criar uma nova tabela com eles.
-
Os atributos removidos devem ser dependentes da chave primária da nova tabela .
| Terceira Forma Normal |
Em primeiro lugar, para que a terceira forma normal seja obedecida, a segunda forma normal deve ser satisfeita também. A terceira forma normal (3a FN) diz que cada atributo não chave é dependente da chave primária e que todos os atributos não chave são independentes entre si.
Vamos supor que exista um cadastro de propriedades rurais de um certo grupo de pessoas. Cada propriedade possui um código, está localizada em um estado brasileiro, ocupa uma certa área e seu preço de venda é função desta área. Esta tabela poderia ser construída como mostramos abaixo:
| Código_Propriedade | Nome_Estado | Área | Preço |
A chave da tabela é o atributo Código_Propriedade. Como dissemos anteriormente, o preço de cada propriedade é dependente do atributo Área, que não é a chave desta tabela. Desta forma, podemos dizer que esta tabela não está na Terceira Forma Normal. Para que a Terceira Forma Normal seja obedecida, devemos remover o campo Preço. Uma vez que o preço de venda pode ser obtido em função da área da propriedade.
| Código_Propriedade | Nome_Estado | Área |
Podemos definir o seguinte procedimento para verificar se uma tabela obedece à terceira forma normal.
Procedimento (Terceira Forma Normal)
-
Identificar todos os atributos que são dependentes de outros atributos não chave e removê-los das tabelas.
| Exemplo Final |
Apresentamos a seguir um exemplo para você recordar todos os conceitos aprendidos neste módulo e vivenciar um pouco da prática de modelagem de bancos de dados. Suponha que você tenha o seguinte problema:
Problema:
Você foi designado para projetar o banco de dados de uma página de comércio eletrônico. Você deve registrar dados dos pedidos dos clientes feitos pela Internet.
Dados de Entrada:
Os dados que você tem que armazenar são:
-
Número de cada pedido
-
Data do pedido
-
Código do cliente que fez o pedido
-
Nome do cliente
-
Endereço do cliente
-
Código de cada produto pedido
-
Nome de cada produto pedido
-
Quantidade de cada produto pedido
-
Preço de cada produto pedido
-
Valor total por produto pedido
-
Valor total do pedido
Inicialmente, devemos pensar na modelagem deste problema. A princípio, poderíamos modelar todos os dados como pertencentes a apenas uma entidade chamada Pedido, por exemplo. Esta entidade está mostrada na figura abaixo:

Se observarmos bem, esta entidade não está de acordo com a Primeira Forma Normal, pois há atributos repetidos. Por exemplo, se em um mesmo pedido um cliente comprar vários produtos, haverá repetição dos dados do pedido. Para resolver este problema então, devemos criar duas entidades, uma que conterá os dados do pedido e outra que conterá os dados de cada produto comprado. Abaixo, mostramos as novas entidades (Pedido e ItemPedido) com suas respectivas chaves:
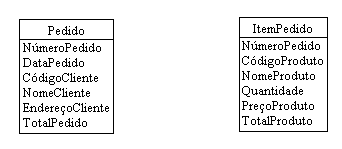
O processo de normalização fica muito mais claro se conhecermos as chaves de cada entidade. O pedido é identificado pelo seu número e cada item do pedido depende do número do pedido e do código do produto que ele contém. Mostramos abaixo as entidades com suas respectivas chaves.
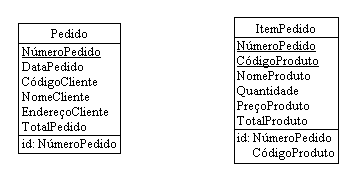
Para verificarmos se as entidades estão de acordo com a Segunda Forma Normal, devemos ver se todos os atributos não chave são totalmente dependentes da chave primária. Por exemplo, o atributo NomeProduto da entidade ItemPedido não depende totalmente da chave primária desta entidade, depende apenas de parte dela (do atributo CódigoProduto). Além disso, a entidade Pedido também não se encontra na Segunda Forma Normal. Por exemplo, o atributo EndereçoCliente não depende diretamente da chave primária e sim do atributo CódigoCliente. Para que nossa modelagem satisfaça então a Segunda Forma Normal, devemos criar uma outra entidade para armazenar os dados dos produtos e outra para armazenar os dados dos clientes como mostramos abaixo:

Desta forma ainda, podemos ver que a modelagem não satisfaz a Terceira Forma Normal. Os atributos não chaves das entidades Pedido e ItemPedido não são independentes entre si, por exemplo, o atributo TotalProduto depende do atributo Quantidade e do atributo PreçoProduto da entidade Produto, ou seja, é dependente de um atributo não chave da entidade. O mesmo acontece para o atributo TotalPedido da entidade NúmeroPedido. Para que a modelagem esteja de acordo com as três formas normais então, devemos então eliminar esses atributos. Mostramos abaixo, a modelagem correta e com os relacionamentos criados.
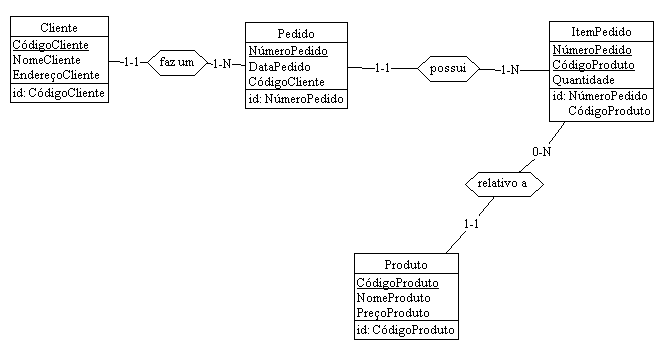
Nossa modelagem agora está conforme as três formas normais. A partir deste ponto então, podemos construir as tabelas de nosso banco de dados.
As tabelas são construídas a partir das entidades definidas anteriormente. Abaixo, temos a definição dos campos da tabela Cliente.
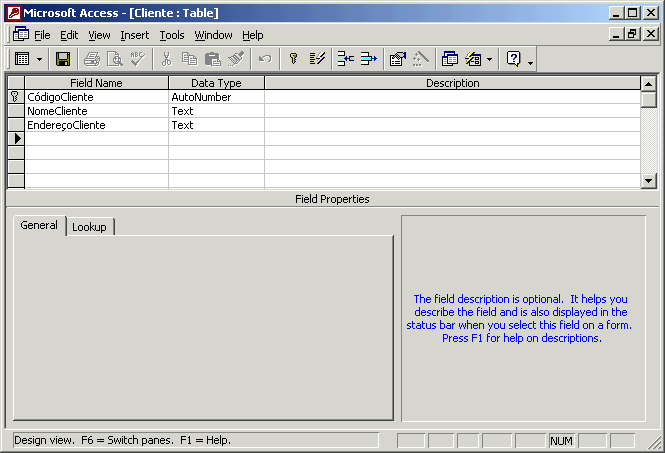
Após a definição das tabelas, devemos criar os relacionamentos entre elas.
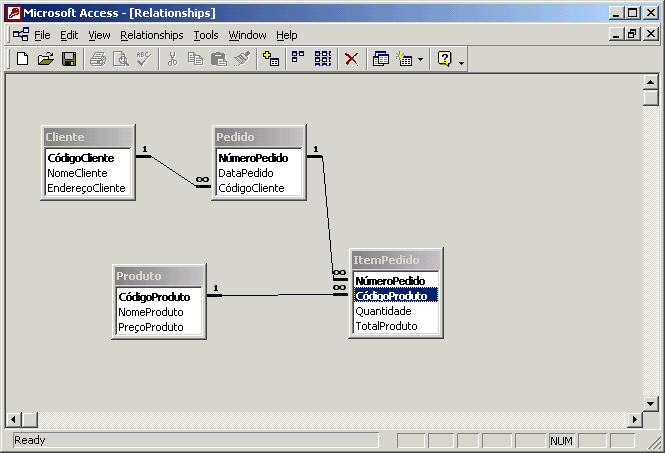
Uma vez definidas as tabelas, valores poderão ser inseridos nas mesmas. Desta forma, você pode fazer consultas neste banco de dados, gerar relatórios e formulários.
Neste módulo, você aprendeu a modelar bancos de dados e a utilizar sistemas gerenciadores de bancos de dados. Esses conhecimentos adquiridos serão muito importantes em sua vida profissional.